Compiler pipeline, language genealogy, and why grammars matter
These figures come from a programming languages / compiler design textbook I was reading for a course. I kept the photos as a single reference page: how compilation is staged, how today’s languages relate historically, and where syntax stops being enough — you need precedence rules, disambiguation for things like else, and attributes for semantics such as types.
Compiler pipeline
The usual story: source program → lexical analyzer (tokens) → syntax analyzer (parse trees) → intermediate code (with semantic analysis) → optional optimization → code generator → machine code on a computer, plus input data and results. A symbol table sits beside the front phases and feeds the back end.
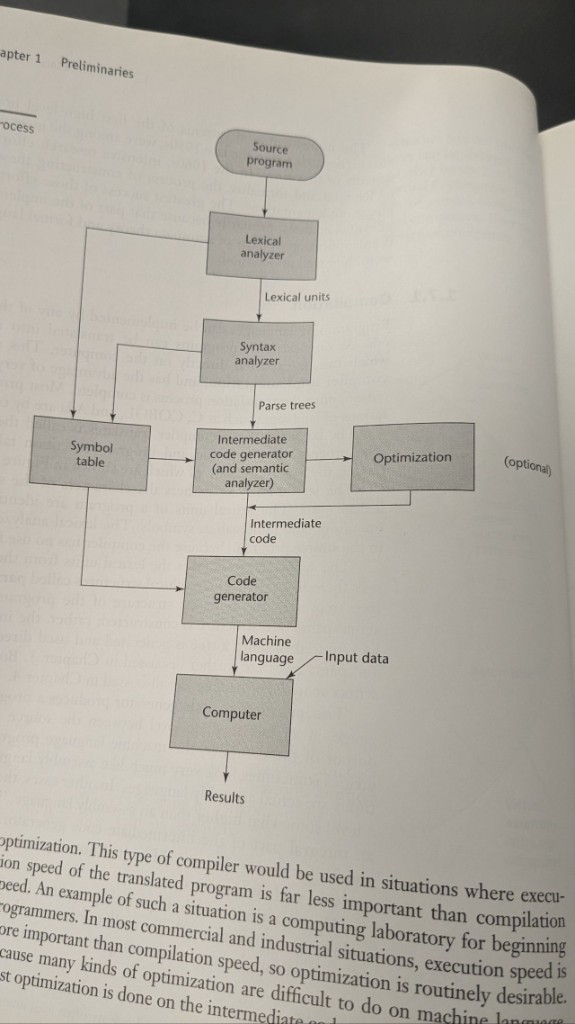
Optimization is optional in the diagram for a reason: teaching compilers and fast edit-compile-run loops often skip heavy optimization; shipping compilers for production workloads usually invest there, often on intermediate code where transformations are easier than at the machine-instruction level.
Genealogy of high-level languages
The second figure is a timeline graph: languages as nodes, arrows as influence or direct descent. You can read off major threads — Fortran, ALGOL as a hub, C as another hub feeding C++, Java, C#, Perl / PHP / JavaScript, LISP → Scheme → ML → Haskell, BASIC toward Visual Basic, plus COBOL, Ada, Prolog, and others.

It is a reminder that “picking a language” is also inheriting syntax habits, runtime models, and communities shaped by decades of prior design.
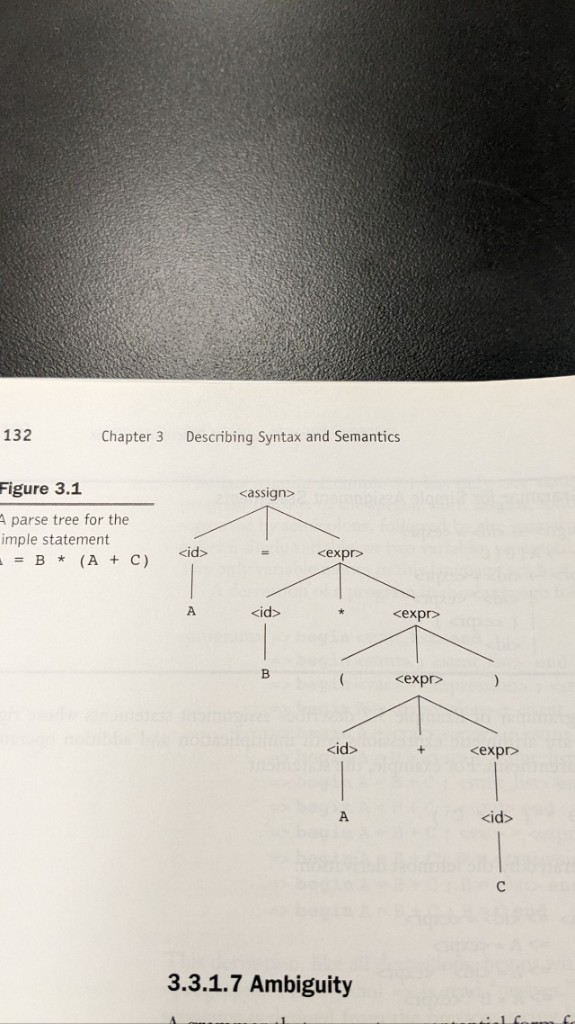
Parse trees and one unambiguous assignment
For the statement A = B * (A + C), a parse tree makes the grouping explicit: the + sits under the parenthesized subexpression, and * combines B with that whole subexpression before assignment. The tree is the artifact the syntax analyzer hands to later phases.
Ambiguity: two trees for A = B + C * A
The textbook’s classic contrast: the same token string can correspond to two different trees if the grammar allows it. One tree groups like B + (C * A) (multiplication tighter than addition); the other like (B + C) * A. Only the first matches ordinary arithmetic precedence.
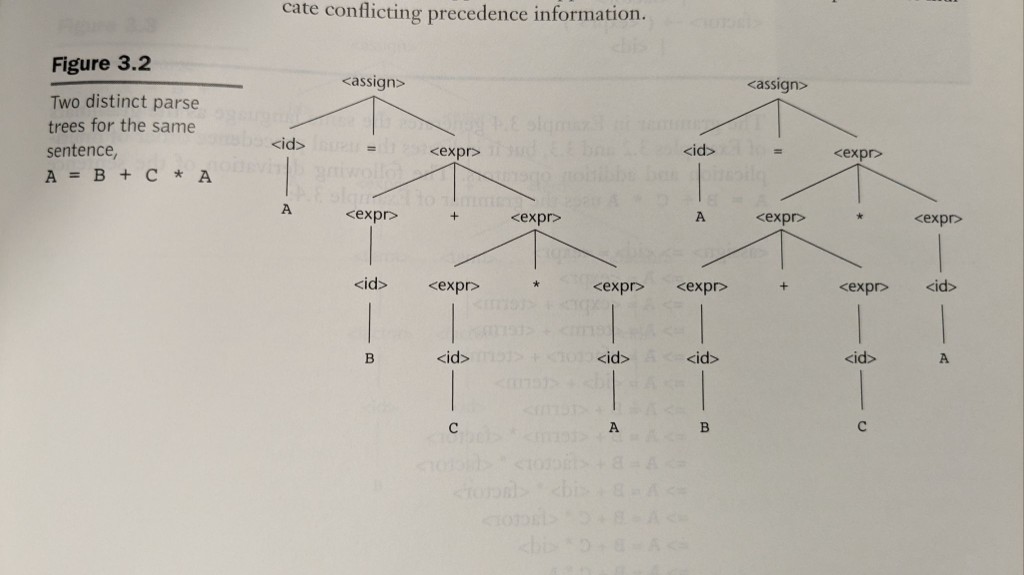
Real grammars fix this by stratifying expressions (separate nonterminals for terms and factors, or precedence declarations in parser generators) so the parser cannot build the wrong shape.
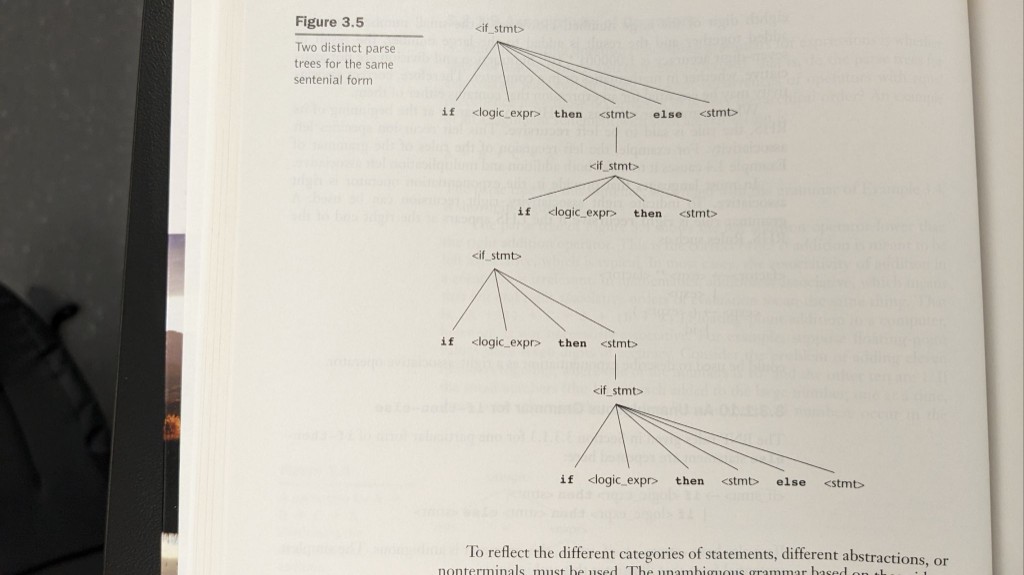
Dangling else
A second ambiguity class is structural, not arithmetic: nested if with a single else. One parse attaches else to the outer if; the other to the inner if. Languages adopt a concrete rule (most often: else binds to the nearest if) and/or require braces or end if markers so the intent is syntactically unique.
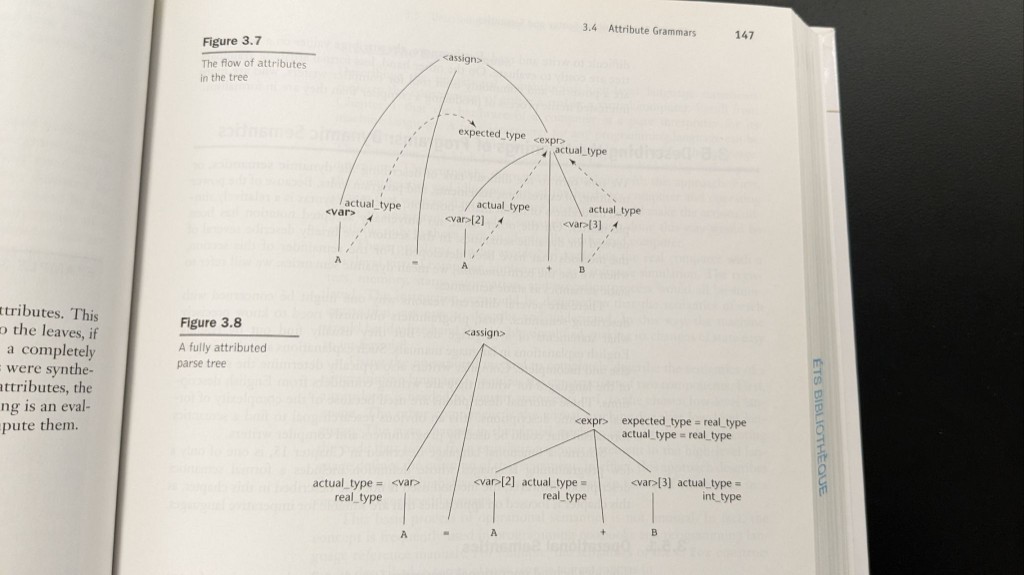
Attribute grammars: types flow through the tree
Syntax alone does not carry types or meaning. Attribute grammars decorate the tree: synthesized attributes bubble up (for example, the actual type of an expression from its leaves), and inherited attributes push context down (for example, the expected type from the left-hand side of an assignment). The book’s example with A = A + B shows expected_type on the expression and actual_type on each var, which is exactly how a compiler justifies coercions or reports errors.
If you are revisiting the same chapters: the through-line is pipeline first, then history for context, then formal syntax (trees), then where syntax breaks (ambiguity), then how semantics attach (attributes). These scans are my own study aid; the original figures and prose belong to the respective textbook and publisher.
Related: course notes on the software life cycle — GOALS, waterfall, verification vs validation.